 Monocular Visual-Inertial Depth Estimation
Monocular Visual-Inertial Depth Estimation
Monocular Visual-Inertial Depth Estimation
Monocular Visual-Inertial Depth Estimation
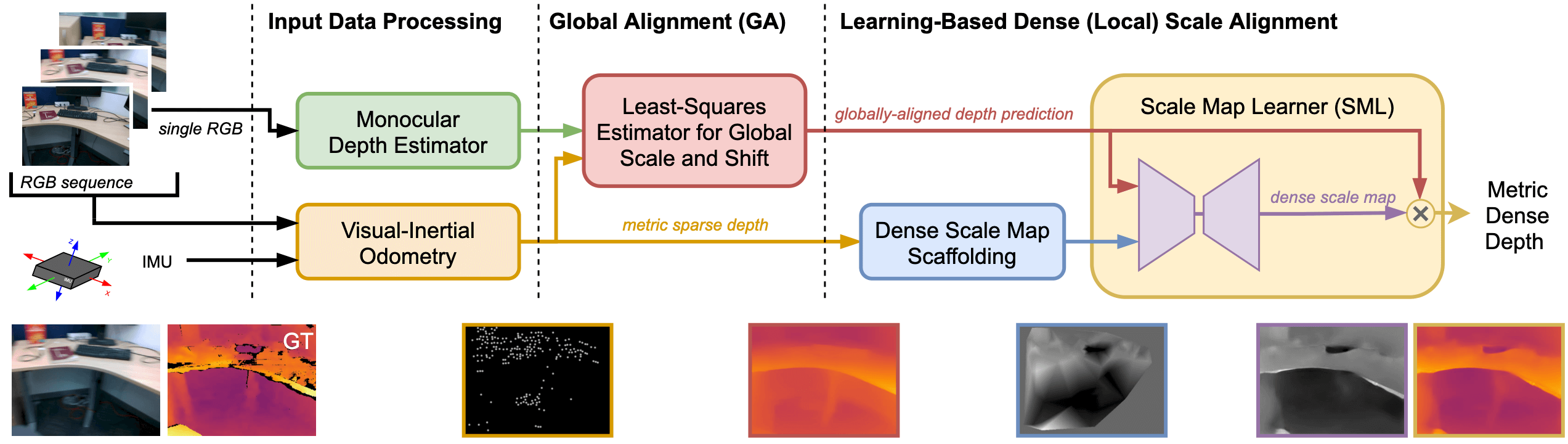
We present a visual-inertial depth estimation pipeline that integrates monocular depth estimation and visual-inertial odometry to produce dense depth estimates with metric scale. Our approach performs global scale and shift alignment against sparse metric depth, followed by learning-based dense alignment. We evaluate on the TartanAir and VOID datasets, observing up to 30% reduction in inverse RMSE with dense scale alignment relative to performing just global alignment alone. Our approach is especially competitive at low density; with just 150 sparse metric depth points, our dense-to-dense depth alignment method achieves over 50% lower iRMSE over sparse-to-dense depth completion by KBNet, currently the state of the art on VOID. We demonstrate successful zero-shot transfer from synthetic TartanAir to real-world VOID data and perform generalization tests on NYUv2 and VCU-RVI. Our approach is modular and is compatible with a variety of monocular depth estimation models.